
TL;DR
I tested Stable Audio 2.5 the way any non‑musician would: I wrote simple descriptions, hit generate, and asked for tiny tweaks. In about half an hour, I producedThree assets I’d actually publish—without knowing a thing about BPM or keys. My verdict is that Stable Audio 2.5 makes professional‑sounding stings, loops and beds almost effortless for creators like me. The main thing I still want is a little more control over volume and vibe presets, but overall, this version is a huge step forward for non‑musicians.
Introduction: Why I’m Reviewing Stable Audio 2.5
As someone who runs a blog for creators and marketers, I care less about technical breakthroughs than about whether these tools actually save time. I don’t have a background in audio production, and I don’t want to learn one just to get a clean logo sting or a gentle background bed for a product video. So this review is written from the perspective of a non‑musician who needs usable results fast. I’ll walk through my test process, share my exact prompts, and leave space for your own observations and screenshots so you can replicate or tweak my workflow.
What Stable Audio 2.5 Is (and Isn’t)
Stable Audio 2.5 is an AI model that takes text prompts and generates audio clips. You can describe mood, length and instrumentation in plain English, and it will produce a track that matches your description. The upgrade from version 2.0 to 2.5 focuses on speed and enterprise‑ready quality. Stability AI says the new model uses an Adversarial Relativistic‑Contrastive (ARC) post‑training method to reduce generation steps from 50 to 8, which is why it can create tracks in seconds.
The model can generate songs with separate intros, builds and outros and responds better to prompts describing moods (“uplifting”) or genre blends (“rich synthesizers”). It also allows audio inpainting—upload a clip and have the tool extend or fill it in context. According to the launch, the training data are fully licensed to ensure commercial safety.
What it’s not: this is not a vocal model for melodies and lyrics. Stable Audio 2.5 doesn’t try to clone voices or sing; it’s designed to create backgrounds, stings, loops and instrumental beds. If you need spoken narration, you’ll still pair this with a text‑to‑speech tool (like ElevenLabs or your own voice).
How I Tested It
I created a structured test to simulate common tasks for content creators. I generated three types of audio: a 60‑second voice‑over bed,a 45‑second cinematic bumper, and a 90‑second product‑demo bed. For each, I wrote a prompt in plain English, listened to the first output, and made exactly one revision using a simple instruction like “softer overall” or “clean ending.” My goal was to see how quickly I could go from idea to final, publishable track and whether I needed to know any music theory to get there.
The Prompts
1) Voice‑Over Bed – Sixty Seconds of Calm Support
Prompt: Create 60 seconds of calm background music for a voiceover. Keep it gentle and simple, strictly instrumental, no sudden changes. Make sure the speech will sit clearly on top. End smoothly at exactly 60 seconds.
I am not highly satisfied with the output, so I edited it, “Make it a bit softer overall; keep everything else the same,” and the regenerated track had more space. The bed ended neatly at 60 seconds and didn’t fade out awkwardly, which meant I could drop it under a voice track without worrying about a long tail.
2) Cinematic Bumper – Forty‑Five Seconds of Lift
Prompt: Make a 45-second cinematic bumper that feels positive and confident. Gentle rise in the middle, then a clean, satisfying ending at 45 seconds. Instrumental only.composition, 90 BPM
This track had a warm opener and a gentle swell around the middle, then resolved confidently. It was exactly the kind of cue I’d run under a title card or feature reveal. I Really Like this output.
Where to add screenshots: show the bumper result card or waveform and highlight the 45‑second duration. If you changed the ending, show a before‑and‑after screenshot or annotate the difference.
3) Product‑Demo Bed – Ninety Seconds That Respect Speech
Prompt: Make a 90-second background track for a product demo. Smooth, professional, not distracting, instrumental only. Keep a consistent feel and finish with a clear ending at exactly 90 seconds.
The first output was pleasing but slightly forward in volume. I asked, “Lower the overall loudness slightly so voice sits on top; don’t change the arrangement,” and the result hit the sweet spot: the same melodic line, now sitting comfortably under dialogue. This track is exactly what I’d run under a screen recording. It ended cleanly at 90 seconds, which saves me trimming time.
Tiny Edits, Huge Gains: The Power of One‑Line Fixes
I found that very simple changes in plain English make huge improvements sometimes. I have used a few of them in this experiment, some in my personal use. They are like short directives that anyone can repeat:
- “Make it slightly softer overall; keep everything else the same.”
- “Remove any click at the loop point.”
- “Slightly stronger finish; same instruments, same length.”
- “Lower overall loudness so voice sits on top; don’t change the arrangement.”
- “Keep the same palette; extend to [new length] and add a clean ending.”
These one‑liners worked because the model responds to plain English. If something is too busy, say “simpler.” If the ending feels smeared, say “clean ending.” You don’t need to mention BPM, keys, or technical audio terms. As Stability AI points out, the model is designed to interpret mood and structural instructions, which is why this kind of language works so well.
Time, Effort and Value
From the first prompt to three finished assets, I spent about 15 minutes and made 4 total revisions. I never opened a professional audio workstation until the end, and there were no painful trims. For perspective, licensing comparable stock audio or commissioning a custom track can take hours or days. With Stable Audio 2.5, I got publishable audio in less than a coffee break. The cost depends on your subscription or API tier; however, the value in time saved is obvious. Enterprises can generate dozens of variations in minutes rather than weeks, and that same efficiency trickles down to individuals.
Scorecard (Fill In Your Ratings)
| Category | Rating (1–5) | Notes |
|---|---|---|
| Speed | 4.4 | Fast but not as much as I expected (I am using Free version) |
| Ease of Use | 5 | Plain English prompts; no jargon needed. |
| Usefulness | 4.5 | Ready‑to‑publish assets for multiple formats. |
| Originality/Safety | Can’t tell exactly, as it needs quite extensive use but so far good . No known melody comes accross yet | |
| Value | 4.3 | Time saved vs. stock/library searches. |
Licensing & brand safety
Everyone, from individuals to Enterprises, should care much about the chain of rights as they do about the waveform. Stability positions Stable Audio 2.5 as “commercially safe,” trained on a fully licensed dataset, which is the headline legal claim you will take to procurement. In addition, the company calls out content recognition and Terms of Service that require uploads to be free of copyrighted material. Everyone must Read Important Document Like Terms of Service and other Important documents, like privacy Policy, before using it.
What’s Still Missing (Personal Wishlist)
While the tool impressed me, there are a few areas that would make it even better:
- Presets for Voice‑Over Beds: A slider or preset to set bed loudness would avoid manual volume tweaks.
- Simpler Budget Control: A way to specify track length and mood, then choose a “price” in tokens or seconds would help creators manage generation budgets.
- Customizable Vibe Tags: Let users save their own vibe tags or templates (e.g., “calm professional”) so they don’t have to rewrite prompts.
Future versions might also integrate deeper control over evolution or layering, but right now, the plain‑English interface is the star. Stability AI has indicated that future research will explore real‑time and adaptive audio, which could bring dynamic soundtracks that evolve with your content.
How it compares (ElevenLabs audio tools, Adobe, Google)
This model is not trying to be a voice clone first; it is aimed at music, sound design, and production-ready beds. If your primary need is expressive speech,
remains the most recognizable production choice, with strong multilingual voices and robust SSML-style controls, and it is increasingly bundling background audio and effects as part of a voice-agent stack.
Where Stable Audio 2.5 diverges is in its ability to spit out full musical structures and loopable textures at enterprise speed, then continue or repair a segment via inpainting.
the comparison is more about workflow than pure generation.
Adobe’s advantage is deep timeline integration, asset management, and guardrails across Creative Cloud; Stable Audio 2.5, by contrast, is a generator you drop into Premiere, Audition, or After Effects as a source of licensed beds and stings you can cut to.
the most relevant baseline for enterprise is low-latency TTS in Gemini 2.5 Flash, which is optimized for fast, controllable speech synthesis and predictable pricing, but it’s not a substitute for brandable music or evolving instrumental beds.
That division of labor is a feature, not a bug: use voice specialists for narration, and use Stable Audio 2.5 when you need original music cues, transitions, and background textures that react to timing notes and regenerate in seconds. In practice, an enterprise stack could pair Gemini or ElevenLabs for voice with Stable Audio for the soundbed, and assemble the package in Adobe for finishing and compliance.
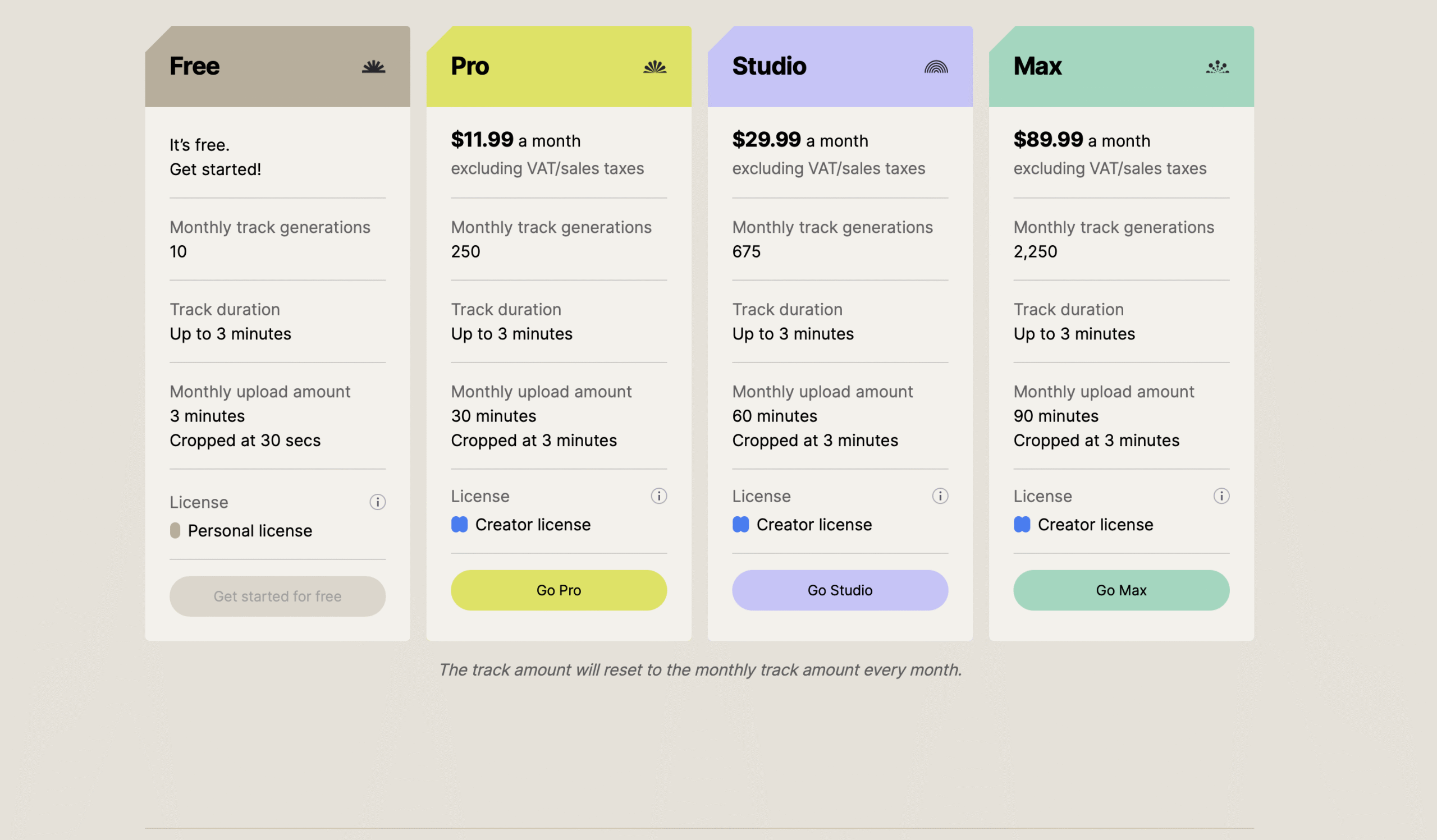
Pricing & limits
Pricing depends on how you access the model. If you engage Stability directly for an enterprise license, expect a scoped agreement that covers deployment (cloud or on-prem), usage volume, and support, with the familiar trade-off between flexibility and cost predictability.
If you prefer to prototype or integrate quickly, hosted partners now expose 2.5 behind simple APIs. Replicate lists the model with standard run-based billing, making it straightforward to wire into internal tools for batch generation or A/B tests, and the fal platform is already quoting per-generation prices for text-to-audio and audio-to-audio endpoints, which keeps experimentation transparent for finance.
The primary practical limits to watch are track length, generation latency under your actual hardware or API tier, and any caps on inpainting regions or file sizes when you upload stems. Stability’s announcement claims sub-two-second inference for up to three minutes on a GPU; real-world numbers will vary with the instance and queue, but the target is aggressive enough to unlock new workflows such as regenerating multiple alt mixes while a producer stays on the line.
If you are budgeting for a team, do a short pilot: define weekly deliverables, run them through the API for two sprints, track per-asset cost and approval time, and then decide whether to negotiate a direct enterprise license or stick with partner usage-based billing.
Final Verdict
Stable Audio 2.5 turned my non‑musician descriptions into polished audio without friction. It respected my instructions, responded gracefully to simple fixes, and delivered assets I’d actually use. For creators and marketers who want to produce clean background music, short stings and loops without digging through stock libraries or messing with waveforms, this tool is a win. I’ll keep using it for my own projects and will watch eagerly for updates that make it even more intuitive.

